
When Tables Became the Language of Time
Understanding why tables are essential to real-time architectures and modern unification patterns.


For most of the history of data systems, we have organized computation around a false dichotomy.
Is the data batch or streaming?
The question feels natural.
Data arrives either all at once or continuously. Systems evolved to reflect that intuition: batch schedulers for yesterday’s data, streaming engines for what is happening now; separate tools, separate pipelines, separate teams.
Over time, we learned to connect these worlds with increasingly elaborate architectures. Lambda patterns. Replay pipelines. Backfills are glued onto streaming jobs. But despite the sophistication, the divide remained.
Then something curious happened.
The same business logic started appearing twice.
Backfills looked suspiciously like replays.
“Real-time” dashboards eventually needed historical corrections.
And every serious incident revealed the same uncomfortable truth:
The data does not care which path it took.
The system does.
The argument here is not that batch or streaming is superior. Nor that unification comes from adding better glue between them.
It comes from choosing an abstraction that makes the distinction largely irrelevant. That abstraction is the table.
Time, Not Batches: What We Actually Process
Consider what a data system really does. It observes the world and records changes.
Orders are placed.
Sensors emit readings.
Users click buttons.
Databases update rows.
None of these events is inherently “batch” or “streaming”. They are simply changes that occur at particular points in time.
A stream is nothing more than an ordered history of these changes.
A table is the accumulated result of applying them.
In short:
A table is the materialization of a stream.
A stream is the history of a table.
Seen this way, a table is not static state. It is a snapshot of understanding at a moment in time. A stream is not a special data structure. It is history.
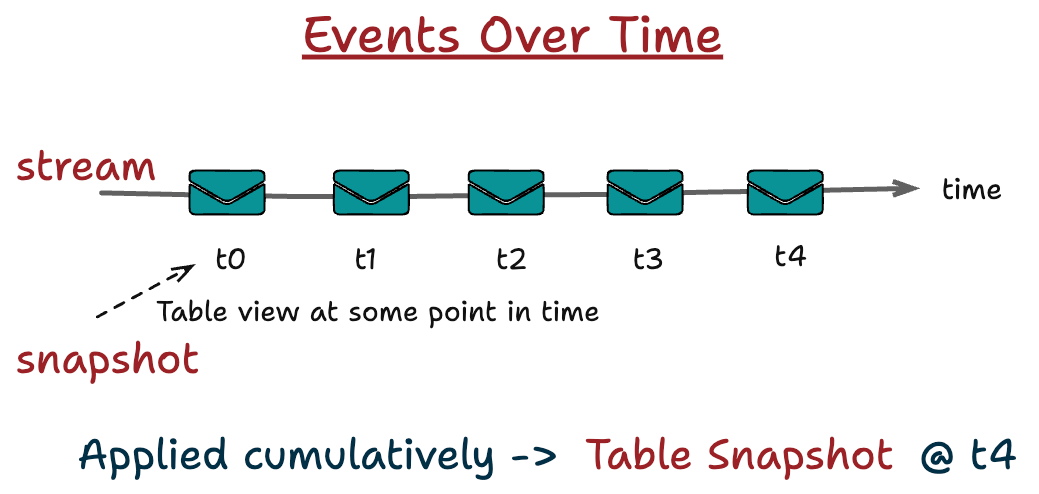
Once you adopt this perspective, the familiar dichotomy starts to collapse.
A batch job is simply applying a finite portion of history.
A streaming job is the same act, performed continuously.
The logic does not change. Only the temporal scope does.
This is the essence of stream–table duality. The phrase itself matters less than the implication: streams and tables are two views of the same reality, separated only by time.
Why Compute Must Be Streaming-First
For this mental model to hold, the compute layer must abandon the idea that batch and streaming are fundamentally different kinds of work.
Apache Flink is notable here not because it popularized the concept, but because it committed to it fully.
In Flink:
All computation is expressed as streaming
Bounded inputs are simply streams that happen to end
The same operators, state model, and semantics apply in all cases
The distinction becomes operational, not conceptual.
Do you stop after producing a result, or keep refining it as new data arrives?
Do you prioritize completeness or immediacy?
These are execution choices, not changes in business logic.

This matters because it eliminates a fork in the mental model. There is no “batch logic” and “streaming logic” that must be kept in sync. There is only logic, expressed once, evaluated over different temporal scopes.
However, this choice comes with trade-offs.
Treating everything as a stream means:
State lives inside the compute engine
Snapshots and reprocessing are compute-coupled
State reuse across jobs is limited
Recovery and backfills are powerful, but operationally heavy
These are not flaws; they are deliberate design choices. But they do raise the next architectural question:
If computation is unified, where does durable truth live?
The Lakehouse as Memory
Every serious data system needs memory.
Not caches, which forget.
Not an ephemeral state, which disappears on failure.
But durable memory, something that remembers not just what is true now, but how it became true.
Modern lakehouses work because they treat storage as a sequence of atomic, versioned table commits.
Each commit represents a meaningful transition in state:
Some arrive continuously from streaming ingestion
Others arrive in large batches from historical loads, reprocessing, or corrections
To the system, these are not different categories of work. They are the same operation: applying new information to an evolving table.
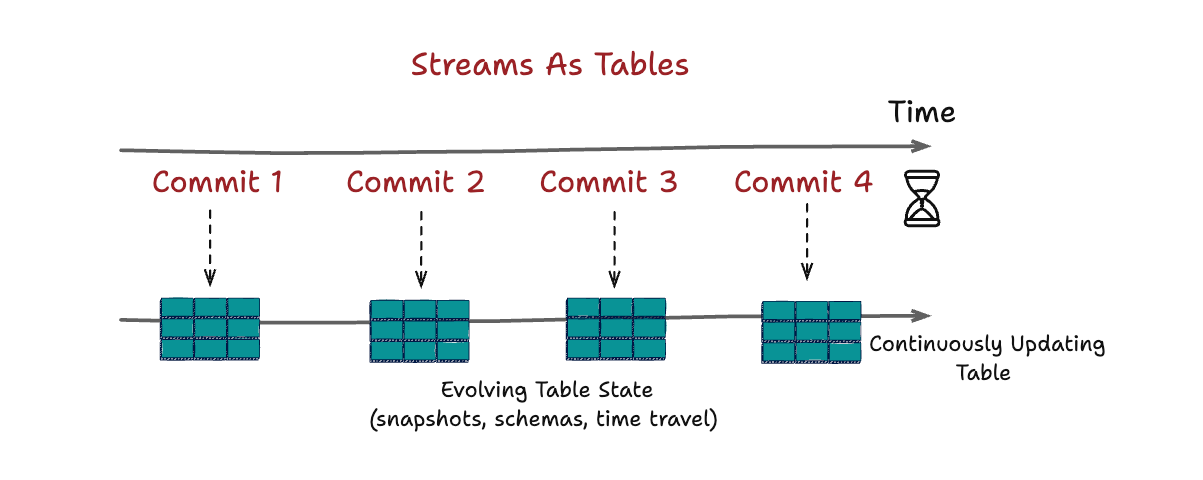
From this perspective:
Backfills are a late-arriving history
Corrections are additional commits
Time travel and reproducibility fall out naturally
Yet despite this progress, there remains a gap between the lakehouse ideal and how most real-time systems are built today.
Kafka and the Limits of Log-Centric Abstractions
Kafka sits at the heart of modern streaming, and rightly so. As a distributed, durable, ordered log, it excels at ingestion, decoupling, fan-out, and replay.
Kafka does offer table-like abstractions:
Compacted topics introduce key-based retention
Kafka Streams model changelogs and materialized views
But they stop short of a full table abstraction.
Kafka does not natively provide:
First-class table schemas with evolution
Updates and deletes as primary operations
Point-in-time snapshots across partitions
Analytical scans and aggregations over stored state
As a result, table semantics are reconstructed around Kafka rather than within it.
Truth always lives downstream.
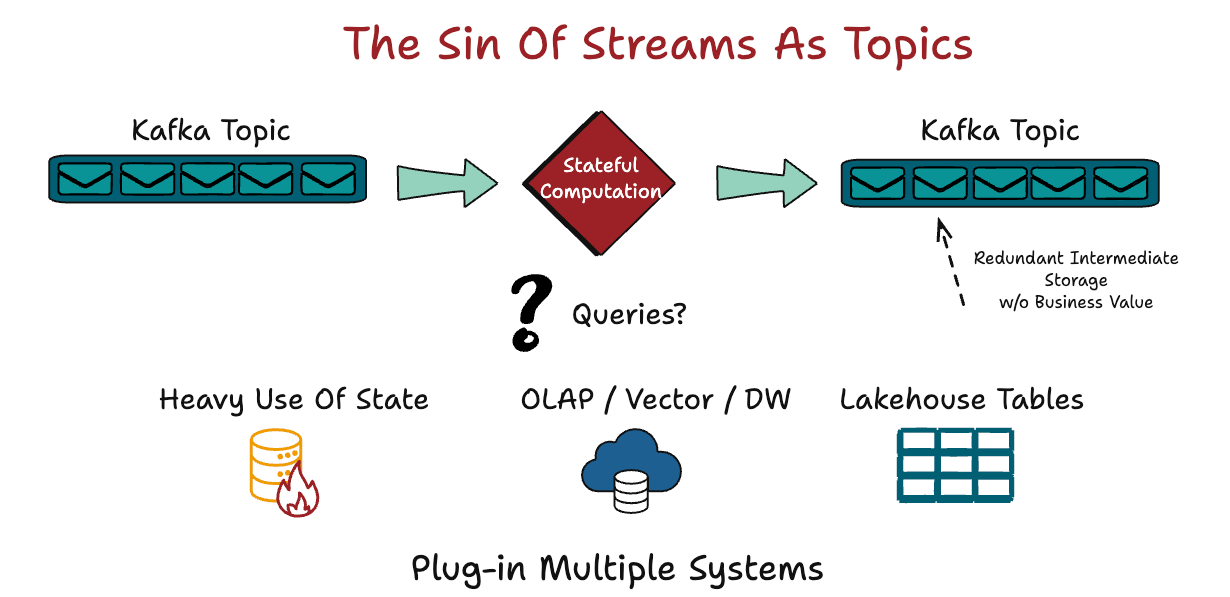
This is why Kafka-centric architectures often look unified on diagrams but feel fragmented in practice. Each consumer reconstructs its own version of state, often with slightly different assumptions, timing, and correction logic.
Logs answer how data moves.
Tables answer what the system believes.
Confusing the two is not a matter of terminology. It is a primary source of architectural friction in modern data systems.
A Concrete Example: Late Refunds and Broken Metrics
Consider a familiar scenario.
A customer places an order on Monday. Revenue metrics update in real time. Dashboards look correct.
On Thursday, a refund arrives due to a delayed fraud decision.
In a Topic-Centric Architecture
The refund event is appended to a topic
Streaming jobs must:
Detect it as a correction
Adjust rolling metrics
Possibly emit compensating events
Batch jobs must be re-run to fix historical reports
Multiple systems now encode “refund logic” slightly differently
The log is correct, but the system’s understanding is fragmented.
In a Table-Centric Model
The refund is an update to the order table
The table evolves to a new version
Real-time dashboards reflect the correction
Historical queries see the corrected snapshot
No special case logic is required
The correction is simply late history applied consistently.
This is the difference between replaying events and evolving state.
Treating Streams as Tables
If tables are the primary abstraction, the real-time data layer must change.
It must:
Understand keys, updates, and deletes natively
Support schema evolution without coordinated redeployments
Allow both continuous consumption and snapshot access
Store data in formats suitable for both real-time access and analytics
Most importantly, it must integrate naturally with the lakehouse so that real-time and historical views are different latencies of the same truth.
This is not an incremental improvement to log-based brokers, similar to how modern solutions try to approach the problems. It is about redefining the streaming storage itself.
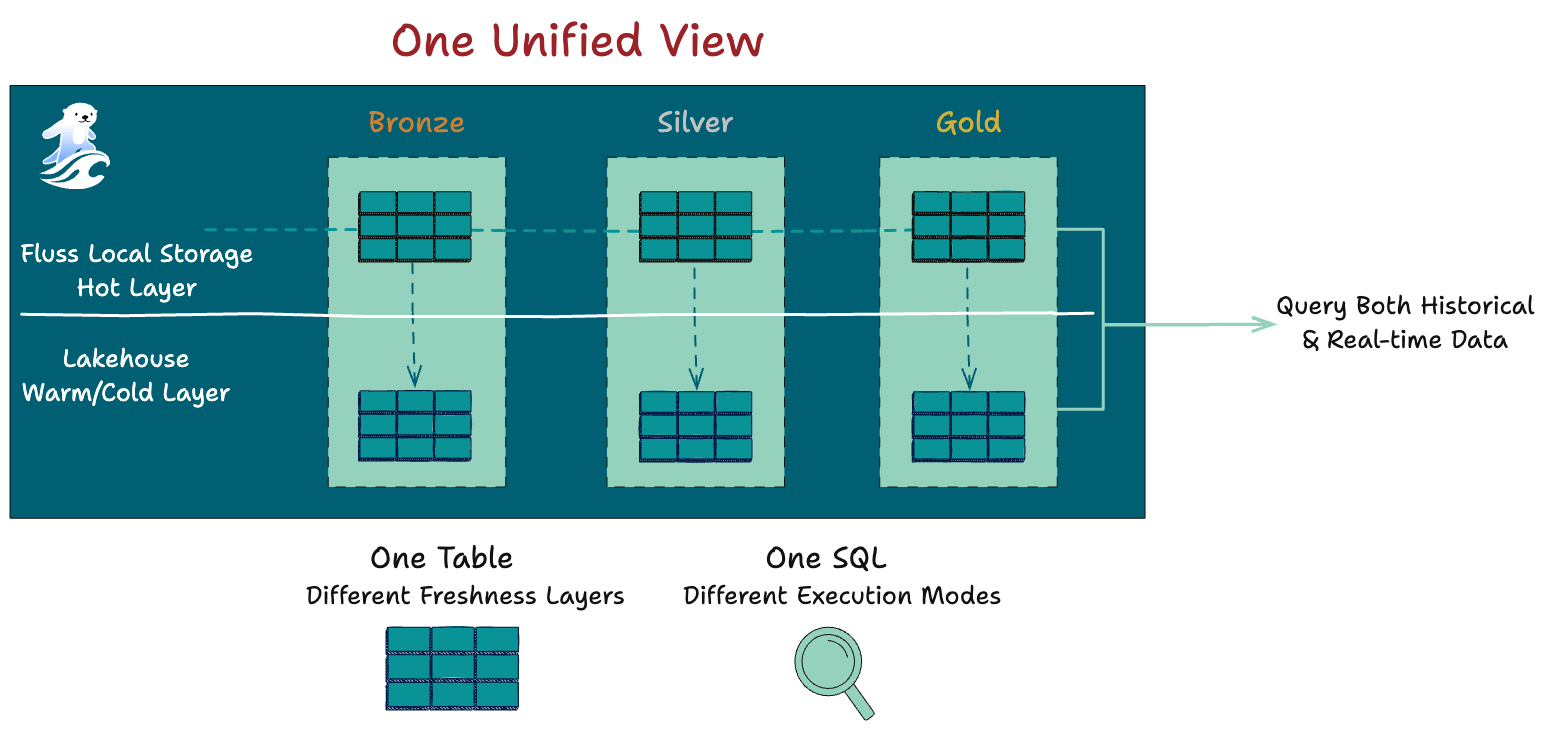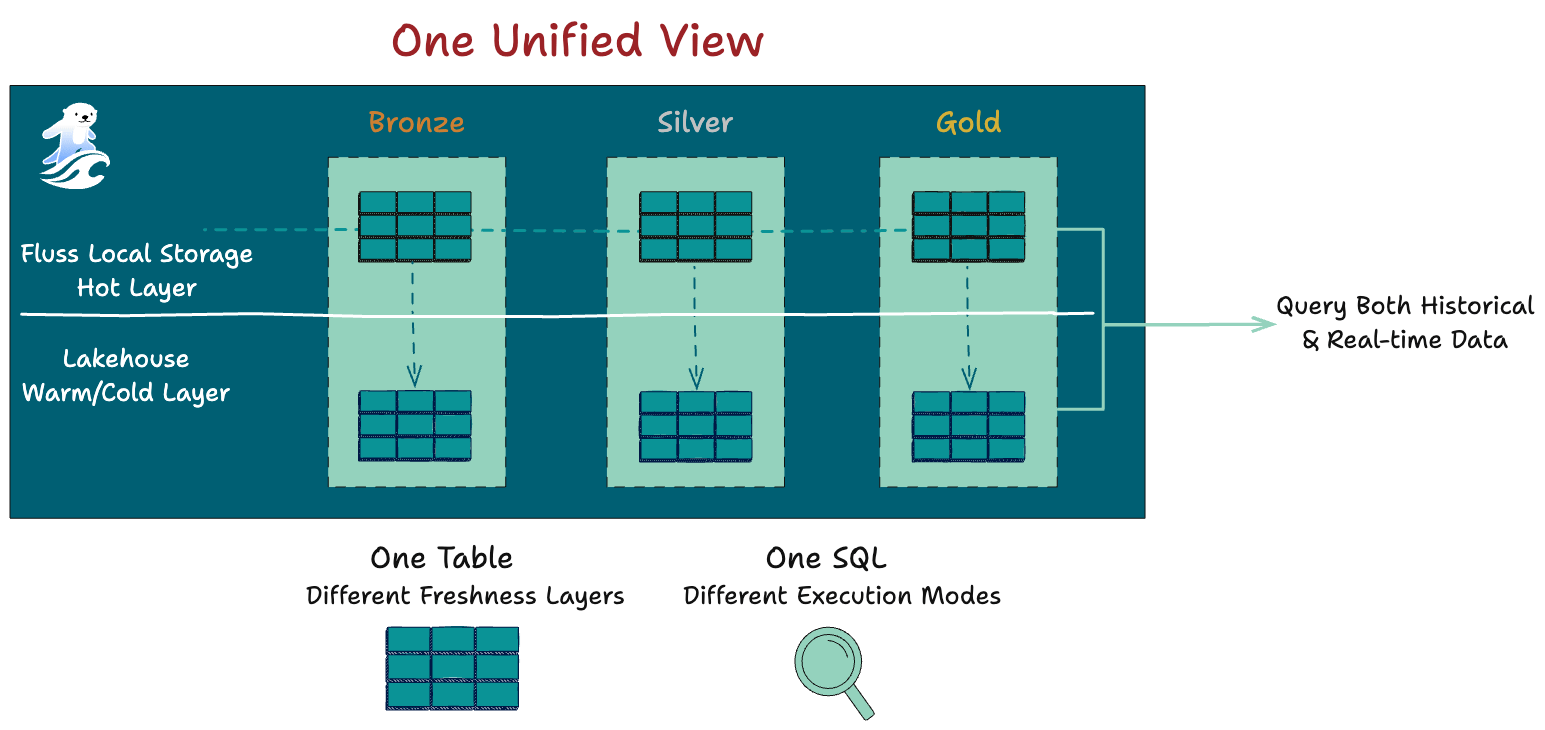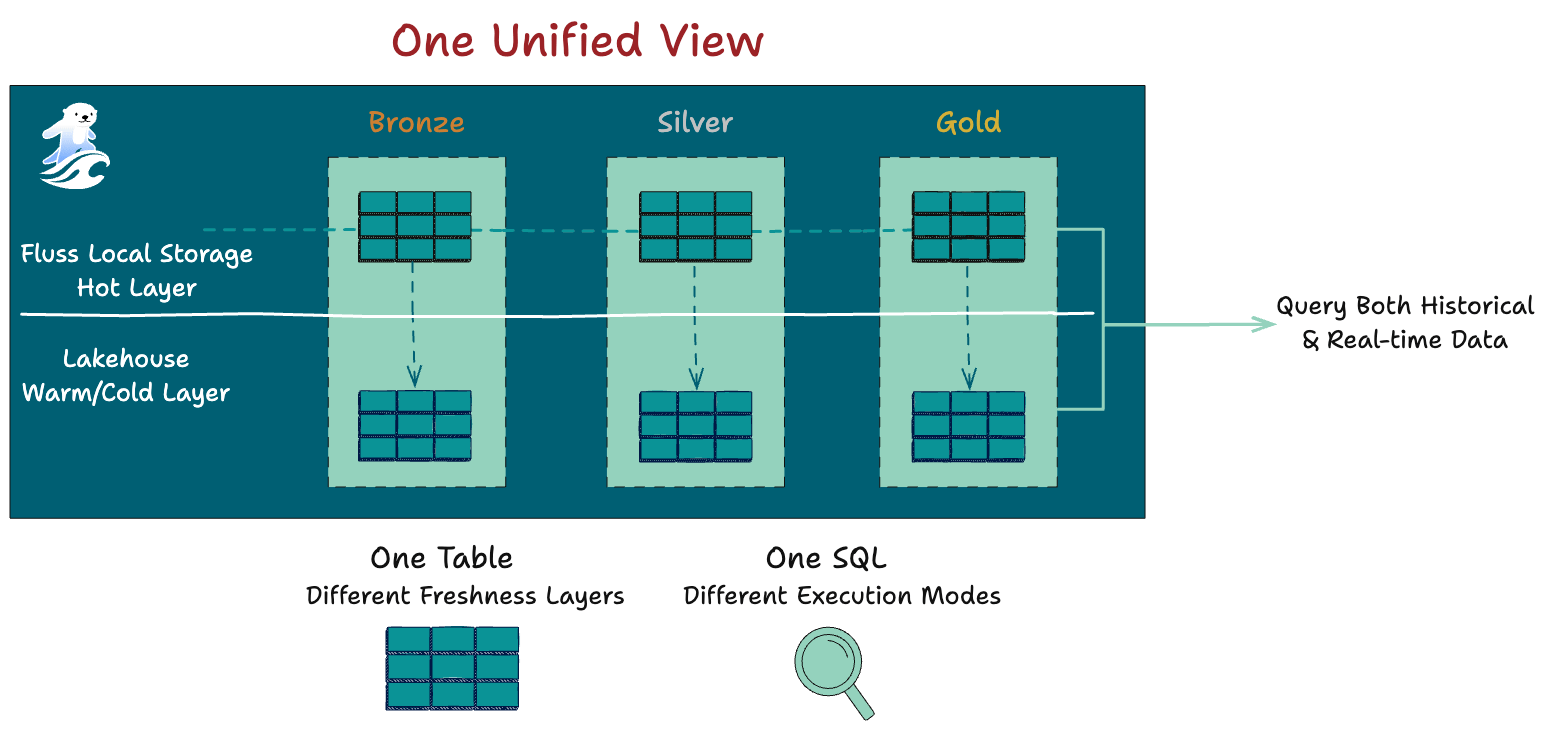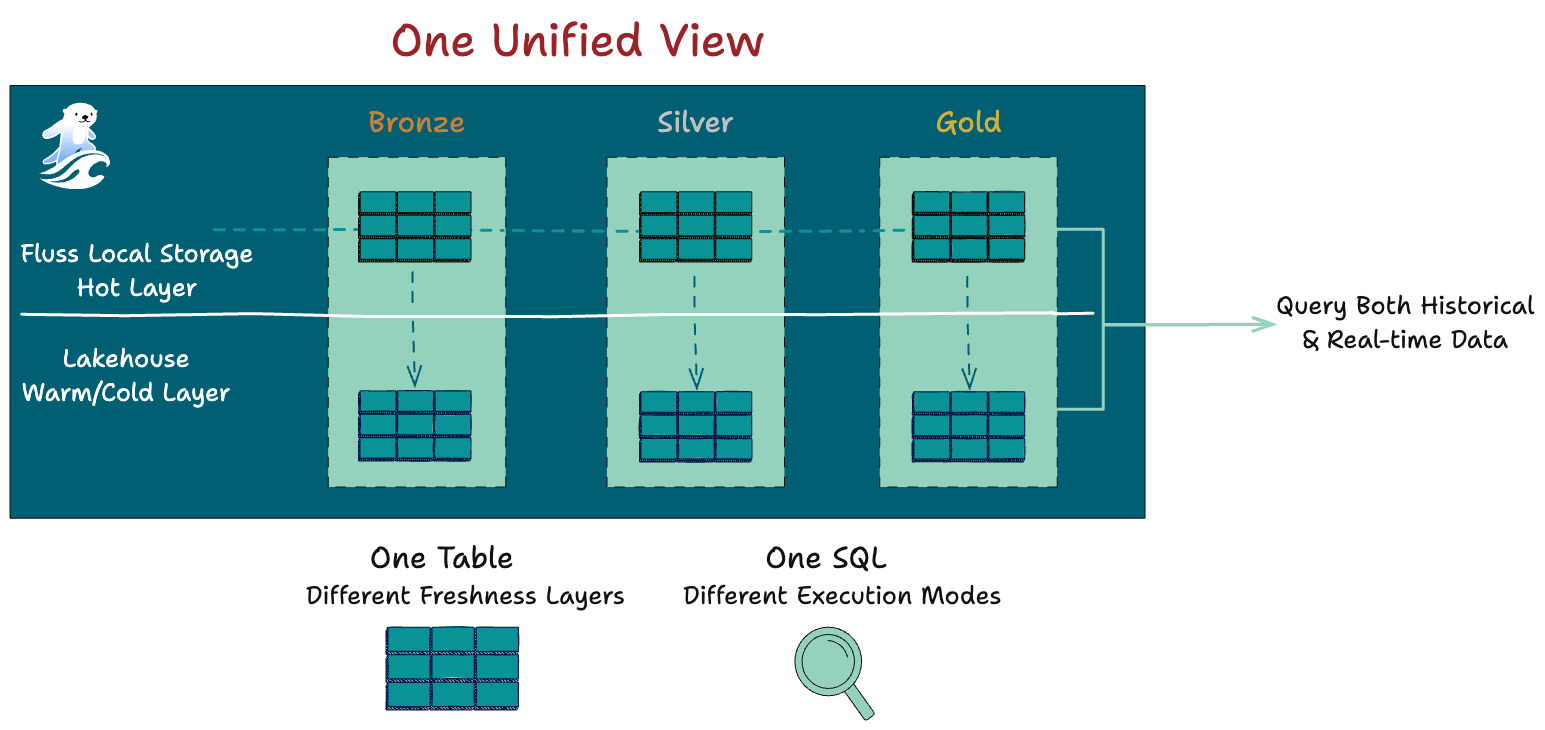
Apache Fluss: Table-First Streaming Storage
Apache Fluss can be understood as a concrete answer to a simple question:
What would a streaming storage layer look like if we started from tables rather than logs? And extend it with columnar properties?
Fluss treats streams as mutable, table-like entities where updates are a natural part of the model rather than an exception.
Columnar storage is a first-class design choice, enabling efficient analytics without sacrificing real-time access.
The system is designed to serve both low-latency streaming workloads and analytical queries, operating as the real-time tier of the lakehouse instead of a transient buffer in front of it.
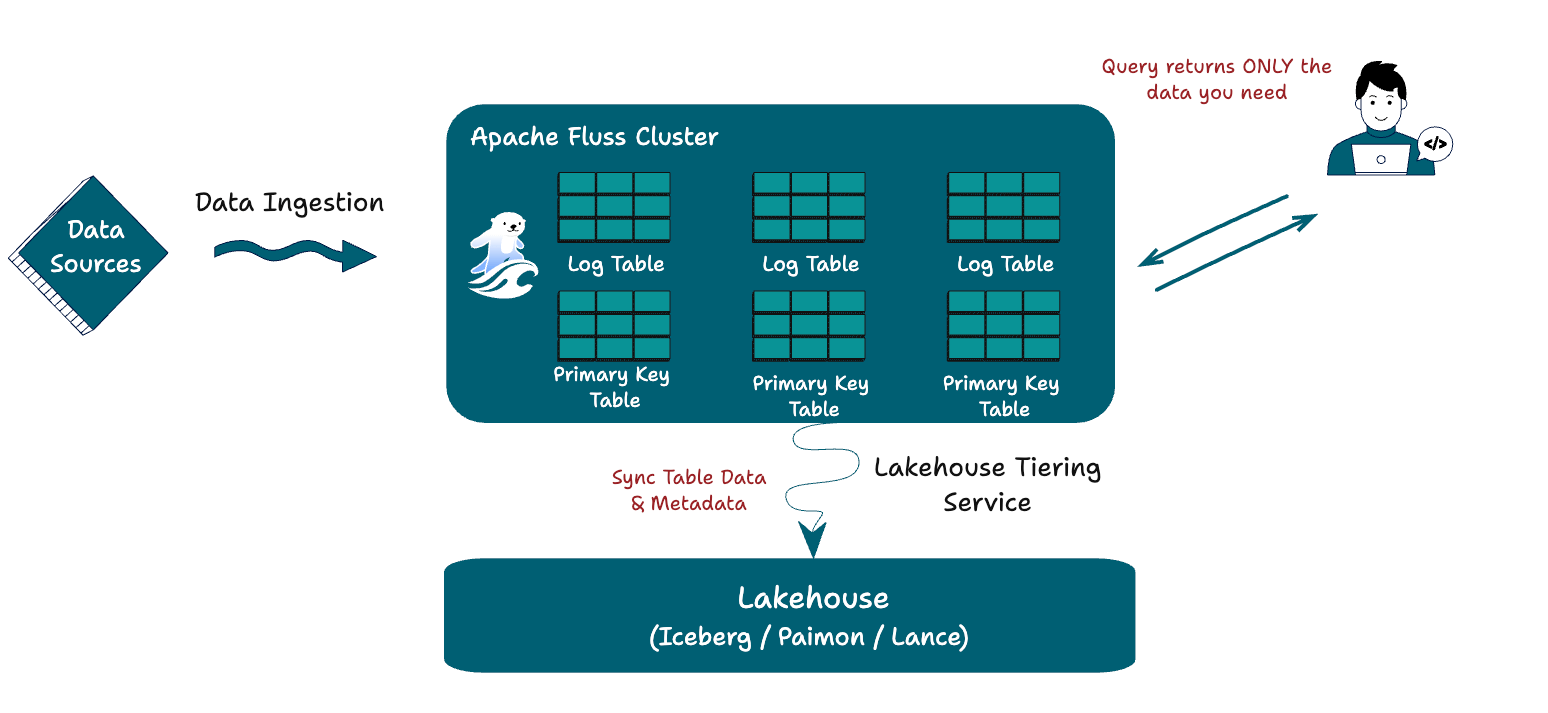
Its tight integration with Flink is intentional. A streaming-first compute engine benefits from a streaming storage layer that shares its mental model of time, state, and evolution.
Together, they form a system in which real-time processing and historical persistence are not opposing forces, but consecutive steps in the same flow.
This is also a great way of separating compute and storage.
Unification as An Emergent Property
When compute is streaming-first, when storage is table-centric, and when the lakehouse serves as the system of record, unification emerges naturally.
Batch and streaming stop being architectural choices. They become runtime characteristics.
A backfill is a bounded stream.
A correction is another commit.
A real-time dashboard is simply a view that values freshness over completeness.
The system does not require special cases to handle these scenarios. It already understands them, because they are all expressions of the same underlying model.
Batch and streaming share the same abstraction, because the world does.
Closing Thoughts
Kafka remains foundational. Logs remain essential.
But logs are not tables.
A log records what happened.
A table represents what is believed to be true.
If we want systems that are consistent, explainable, and accountable over time, we must organize architectures around evolving state, not endlessly replayed events.
Tables are the abstraction that can carry time, history, and meaning together.
When systems are built around continuously updated tables rather than reconstructed logs, batch and streaming stop competing. They collapse into different temporal views of the same reality.
That is what true unification looks like; not a marketing claim that looks good on paper, but an architecture aligned with how change actually happens.